
How can we reorganize the information architecture of the ACM Digital Library to provide a better user experience on the mobile website by creating top-level navigation and improved content structure?
ACM Digital Library
The ACM Digital Library is a research, discovery and networking platform for the Association for Computing Machinery. It has not been optimized for mobile, making it difficult to navigate on-the-go, limiting the user experience to desktop/laptop computers.
The Solution
Our goal was to reorganize the information architecture of the ACM Digital Library to provide a better user experience on the mobile website by creating top-level navigation and improved content structure.
Current pain points on the mobile ACM Digital Library site include:
Lack of central navigation leading to a reliance on search as default navigation
Content not organized in consistent or clear patterns.
Reliance on zooming to view content in a two-column structure.
Overview
Role: UX Researcher
Duration: 10 Weeks
Tools: Optimal Workshop (Card sorting, Treejack testing, Chalkmark testing), diagrams.net (sitemap), Axure (wireframes), Excel (User Testing and Final Analysis), InDesign (Personas)
Methods: Card sorting, Treejack testing, Chalkmark testing, personas, prototyping, and evaluation
Process
Personas
We developed the two personas to inform our design decisions as we developed a mobile information architecture for the ACM Digital Library. Our typical users fell into two categories—student and professor—and we have explored their needs in depth below.


Content Creation
We began our project by performing a content inventory of the website. We then culled our data to use in a card sort. These categories were continually refined through three rounds of card sorting to inform our testing.
Our original content inventory yielded five pages of content (see Appendix A). Many of the items on the homepage were redundant and confusing, and the sheer bulk of unorganized content made navigating the mobile site difficult. As a group, we completed two edits of the data. First, we edited the content for redundancies. Following our initial edit, we realized we deleted too many items and added material back to create third and fourth level hierarchies.
Among the changes we made were the consolidation of multiple items into singular categories and better utilization of browse as a label, as well as the creation of a resources category and a footer to better organize content. These items were then used as categories and levels in our card sort. See Appendix B for the data progression.
Card sorting
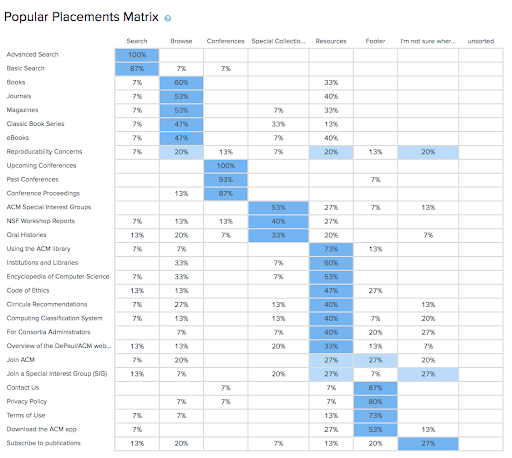


We conducted three rounds of closed card sorts to inform the structure of our navigation. To recruit participants, we posted our card sort on our class discussion board, as well as on the CDM Participant Pool.
Round One
Our first round consisted of 29 cards, and we had 15 student participants. There was no clear pattern among our results, and the only consistent sorting we were able to determine was an overreliance on “I don’t know,”, leading us to re-evaluate our cards and categories.
Based on the results of our first round, we adjusted the language for our categories, shifting search to search resources and browse to browse collection. We further edited our content items to be sorted.
Round two
Our second round consisted of 21 cards, and we had 23 student participants. Once again, we found that “I don’t know” and “resources” categories were overused with our items widely distributed across categories with no clear patterns.
Based on the results of our second sort, we added a category called “Using the ACM library” and removed “resources” to identify how users would sort the information without the “junk” category. We also realized we had deleted too many cards in our efforts to reduce the amount of content for our participants to sort and added content back such as ebooks, journals, past conferences, and reproducability concerns.
Third round
Our third and final sort consisted of 28 cards and 19 users. We found that participants continued to have difficulty categorizing the cards consistently. We decided to update the categories with more familiar language in an attempt to increase the popular placement percentage. The new categories included search resources, browse collection, about ACM, using the ACM library, and the footer.
Information Architecture Testing
We used the results of our card sorting to inform two rounds of treejack testing and one round of chalkmark testing. We made additional recommendations for future iterations based on the results of our chalkmark test.


Treejack testing
We developed a treejack test to evaluate the strength of our initial navigation. We asked the users to complete two tasks:
Task one: Browse the site for a PDF of a specific international conference proceeding titled, "Virtualization in Mobile Computing."
Task two: Search for and view a PDF of an article published by the University of Illinois titled, "A Theoretical Model for Trust in Automated Systems."
We conducted two rounds of treejack testing and recruited our participants using the CDM Participant Pool.
Round one
The initial results of our treejack testing suggested there were issues with our navigation as task one only reported a 14 percent success rate and task two reported a 43 percent success rate. There were seven participants in this initial round of treejack testing.
We believe that the use of browse in task one indirectly led the user to navigate toward browse to begin the task. Additionally, users gravitated towards search as a default way to locate information regardless of structure. We found in task two that most users too started with search on this task; however, they appeared confused by the options under search resources. While the completion rate was higher in this task, it was still low enough to suggest flaws in our navigation.
Following the results of our treejack test, we decided to refine our category names and revise the language used to define tasks. Specifically, we removed search resources and its child elements (advanced and basic search) as these would not be in the navigation, instead serving as a search bar. Additionally, we nestled conferences under browse collection, removed past proceedings because we felt that conference proceedings should suffice, and changed institution to by university for added clarity
Round Two
We had eight participants in our second round of testing and both tasks yielded 75 percent success rates. In both tasks, there still appeared to be confusion about the function of the About ACM category. In addition, users appeared to want to browse by university regardless of the task.
We further considered the function of the About ACM Library category; however, we made no significant changes in our navigational structure as we progressed into the chalkmark testing.
Chalkmark testing
We made changes to our original wireframe based on the results of our testing and conducted one round of chalkmark testing. We recruited participants for our chalkmark testing using the snowball method, drawing on our personal networks in the interest of time. We had 13 participants with an average 73 percent success rate.
Users were asked to consider two scenarios throughout the test, which aligned with the tasks from our treejack test.
We found that users tended to have personal preferences on how they located content. Generally, users either clicked browse to manually locate content or they clicked search. Users who tended to locate content manually wanted to click next to browse additional options rather than filtering in task two. Additionally, there was confusion in regard to the download, leading us to believe we need to provide multiple options to download, with the PDF as the default option.
Sitemap
We developed two iterations of the sitemap based on the results of our testing.
Description of Sitemap and Rationale
The sitemap provided a list of the mobile site’s pages and acted a planning tool for the creation of the wireframes. A sitemap was initially created after we conducted a content inventory of the current ACM Digital Library site and completed round one of the card sort. This sitemap was used to create categories and cards for the round two and three of the card sort test, as well as inform both rounds of the treejack test and the chalkmark tests.
After our initial testing, our results indicated that participants had a difficult time categorizing the cards to our anticipated categories. We decided to condense our categories into two main categories; Browse and About ACM. Subsequently, we placed any facts or information about the site in the footer and allowed the user to search the site using a basic or advanced search feature.
The below sitemap illustrates our final navigation for the mobile site of the ACM Digital Library. This sitemap provides a visual map to differentiate between the top-level navigation, the second- and third-level navigation and available actions (downloading or emailing a pdf). It is fully annotated and provides an overview of each of the actions a user can complete on each page of the mobile site.

Wireframing Process
We developed our wireframes using Axure following the results of our first card sort. We developed three versions of the wireframes based on feedback and test results to use in our chalk mark test.
Our wireframes reflect a clean, one column layout that allows users to easily access content on their mobile devices. Please see below for an annotated look at the content on the homepage. Our interactive prototype is available here: https://bbop7x.axshare.com/#c=2



First iteration - We developed a wireframe following the first card sort, creating an information architecture that closely resembled our results. Our initial design included a relatively large number of second- and third-level categories displayed on the homepage.
We realized our initial design may have been overwhelming to our users because of the sheer amount of content causing the user to be overwhelmed by our initial navigation. We decided to create an interactive wireframe that toggled to show our third-level categories under the 2nd level ones.
Second iteration - Our second iteration of the wireframe incorporated these interactive elements, which gave it a much cleaner appearance. Additionally, we created a footer to remove some of the extraneous content in the top-level navigation. We added two featured publications to provide balance on the page and to break up the content.
We felt these changes provided a better user experience, allowing more focus on the navigational elements to locate content in the ACM Digital Library.
Third iteration - The last iteration of our wireframe was based on feedback from Danyell Jones, UX Architect at kCura, and results from our treejack testing.
We made the following changes:
Moved conferences under browse as that’s where most users
defaulted to find information in our testing.Removed resources as a category, instead using About ACM, to be
more descriptive of the content in the category.Revised featured publication to instead feature a carousel with more
descriptive information about the featured publication to better fit
with our one column layout.
Key Research Insights
Within each test, we refined our navigation based on multiple levels of sub-testing, and we created a sitemap and wireframes, iterating based on our results. Overall, we found that:
Users have personal preferences on how to locate content on the ACM Digital Library: browse or search.
Despite using these websites for educational purposes, users had difficulty navigating based on the formalized labels.
Phrasing can influence a user’s perception of the “right” way to complete tasks.
Next steps for our project would be to continue to refine our navigational hierarchy, performing usability tests in which we ask participants to think aloud to better understand their thought process. We believe that while our testing has been becoming more successful with each iteration, the navigation is not yet ready for implementation and would benefit from more testing.
Project Retrospective
Throughout the project, we were able to see how each stage informed the next from the initial content inventory to wireframing. Additionally, we thought we had clear ideas in terms of categorization and task flows; however, in user testing, we realized this was not the case. We continually had to revise based on the results of our testing, getting closer to clear patterns in our results with each subsequent test. This helped us see the strengths and weaknesses of each part of the process. For example, card sorting does not reveal the same kind of data as treejack testing but both are equally valuable when determining the overall information architecture our mobile site.
Our biggest takeaway from this project was the realization that each part of the process is important for different reasons. This might not have been quite as apparent to us had we gotten fantastic results on our first treejack test. The poor results showed us that while we perceived our card sort results as successful, they did little to inform our assumptions about our process flows. It became obvious that we needed both types of testing to reveal different weaknesses in the information architecture. Even though categories and labelling may seem solid, task flows will reveal additional weaknesses by putting those categories to work in context.fap